Address
304 North Cardinal St.
Dorchester Center, MA 02124
Work Hours
Monday to Friday: 7AM - 7PM
Weekend: 10AM - 5PM
Address
304 North Cardinal St.
Dorchester Center, MA 02124
Work Hours
Monday to Friday: 7AM - 7PM
Weekend: 10AM - 5PM

在人工智能时代,ChatGPT等工具已成为许多组织的首选解决方案,提高了效率和生产力。数据不会说谎:您或您的员工很可能正在使用 ChatGPT起草电子邮件、生成内容、执行数据分析,甚至协助编码。
然而,如果使用不当,这些工具可能会无意中在未来的生成式 AI 模型(例如 GPT-3.5、GPT-4 和最终的 GPT-5)中暴露您公司的知识产权 (IP),这意味着任何 ChatGPT 用户都可以访问该信息。
三星工程师使用 ChatGPT 协助进行源代码检查,但《韩国经济学人》报道了三星员工无意中通过该工具泄露敏感信息的三个不同实例。这导致机密源代码和记录的会议内容最终进入公共领域,可供 ChatGPT 的未来迭代使用(来源)。
当您使用我们的非 API 消费者服务 ChatGPT 或 DALL-E 时,我们可能会使用您提供给我们的数据来改进我们的模型。
在这篇文章中,我们将讨论将 ChatGPT 和 OpenAI 的 API 与公司内部数据结合使用的潜在风险,以及如何尽可能降低公司的风险。我们还将讨论适合您公司的其他选项,例如训练您自己的语言模型来复制 ChatGPT 的功能或使用开源模型。这两个选项都提供了获得 ChatGPT 生产力优势的途径,而无需将数据发送到 OpenAI。
开发人员使用 OpenAI 的完成 API 来创建应用程序并使用 OpenAI 最先进的语言模型,例如 GPT-3 和 GPT-4(为 ChatGPT 提供支持的模型)。这些 API 提供了额外的开箱即用保护级别。与 ChatGPT 不同,您的数据仅由签约的审核团队查看,不会回收到 OpenAI 模型的未来训练中。他们的 API 遵循数据政策,不允许提交的信息用于训练未来的模型(他们的API 数据使用政策规定,您的数据仅保留 30 天以用于滥用和误用监控。然后将其删除。)
但是,根据提交给 API 的数据的性质,您可能会认为使用 OpenAI 的 API 仍然风险太大。最终,OpenAI 员工或承包商将查看您发送到 API 的一些数据,如果其中包含敏感的个人身份信息或个人健康信息,则可能意味着大量麻烦。

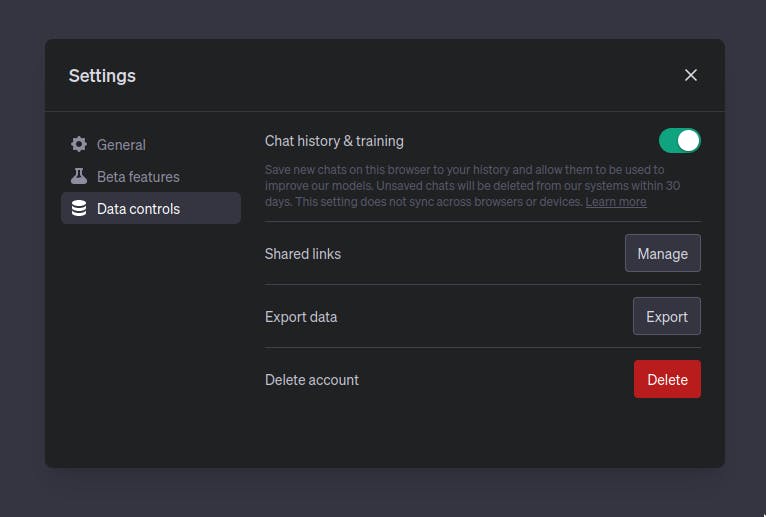
ChatGPT 设置页面上的聊天历史记录和培训按钮
2023 年 4 月底,ChatGPT 发布了一种管理数据的方法,即 ChatGPT 设置中的“聊天历史记录和训练”按钮。关闭此功能后,平台上共享的任何数据都不会用于训练未来的模型。按钮下方有一条注释:“未保存的聊天记录将在 30 天内从我们的系统中删除”。此 30 天说明可能指的是滥用和误用监控政策。这会带来与使用上述 OpenAI 的 API 相同的风险。
一些公司可能会考虑训练自己的模型作为替代方案,效仿三星在数据泄露事件后所走的道路。这种方法可能看起来像是一个灵丹妙药:您可以保持对数据的完全控制,避免潜在的 IP 泄漏,并获得适合您特定需求的工具。
但让我们暂停一下。训练自己的语言模型并不是一件容易的事。它是资源密集型的,需要大量的专业知识、计算能力和高质量的数据。即使在开发模型之后,您仍将面临维护、改进模型并使其适应不断变化的需求的持续挑战。
此外,语言模型的质量很大程度上取决于它们所训练的数据的数量和多样性。鉴于 OpenAI 等公司使用大量数据集来训练模型,单个公司要达到这种复杂程度和多功能性水平具有挑战性。真正成功的公司是像 Bloomberg 这样的公司,他们根据 40 年的财务数据和文档创建了 BloombergGPT(来源)。有时,对于试图获得优势的小公司来说,这些数据是无法获得的。
开源模型的最新技术正在迅速发展。可以下载开源模型并在您的计算机上运行,使其可自行托管,并且无需像 OpenAI 这样的公司参与。
由Open Assistant等组织训练的模型正在产生显着的结果,并且完全开源。他们的社区正在积极收集数据,以参与 OpenAI 与 ChatGPT 所使用的强化学习人类反馈 (RLHF) 循环。该模型的性能令人印象深刻,特别是考虑到它对开源社区(包括我自己的贡献)的依赖。然而,Open Assistant对其模型的局限性非常透明,承认他们的数据偏向 26 岁的男性人口。他们只建议在研究环境中使用他们的模型,在披露这些人口统计数据时表现出负责任的行为。感谢开放助手!
Orca是一个有前途的、未发布的开源模型,由 Microsoft 训练。它比 GPT-3 小,但产生的结果与 GPT-3 相当,有时甚至更好。如果您有兴趣,Orca 上有一段由 AI 提供的精彩视频。但是,您不能使用 OpenAI 的模型来训练您自己的模型,因为这将违反 OpenAI 的服务条款。Orca 明确接受了 GPT-3.5 和 GPT-4 输出的训练,因此微软声称他们将仅出于“研究”目的发布该模型。
这两种模型都是专门为研究目的而设计的,因此不适合商业应用。在审查了其他开源模型作为替代方案后,我发现它们中的大多数要么源自 Meta 的 LLAMA 模型(因此受到相同的“研究”限制),要么太大而无法有效运行。
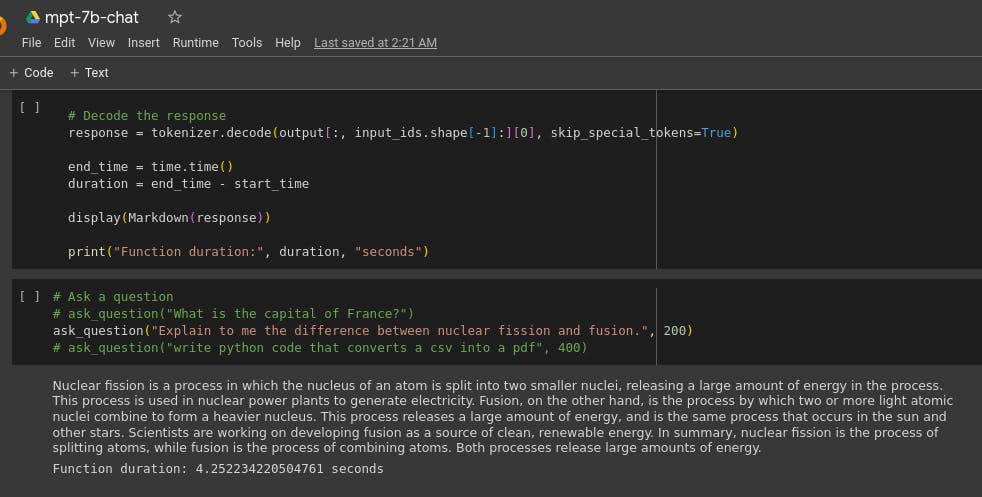
一个令人鼓舞的选择是利用MosaicML等公司来私下托管您的推理。MosaicML 是为数不多的商用开源语言模型之一。他们声称他们的 MPT-30b 模型达到了与 GPT-3 相当的质量。虽然他们没有提供具体的基准,但我倾向于相信他们的说法,因为我和一个朋友开始测试他们的一个较小的模型(MPT-7b),初步结果是有希望的!

MPT-7b-Chat 模型回答有关核裂变和聚变之间差异的问题。它提供了令人信服且完整的答复!
根据您的数据和用例的性质,使用 ChatGPT 或 OpenAI 的 API 可能不适合您的公司。如果您的公司没有关于可以在 ChatGPT 中发送或保存哪些数据的政策,那么现在是开始这些对话的时候了。
在私人企业环境中滥用这些工具可能会导致 IP 泄漏。这种风险的影响是巨大的,从竞争优势的丧失到潜在的法律问题。
如果您有兴趣进一步探索 MosaicML 的模型,这些模型是大型语言模型的开源和商业可用的有限选项之一,请告诉我们!我们有着相同的兴趣,并且很高兴能够共同进一步探讨这个话题。
如果您对使用您自己的公司数据提供安全、检索增强生成的解决方案感兴趣,我们正在开发一款专门设计用于保护您的数据并符合 SOC2 合规性、与您的 SSO 提供商集成、在您的组织内实现对话共享以及执行数据输入政策。我们的最终目标是为您的数据提供 ChatGPT 质量,而不存在任何 IP 泄露风险。
-END-



{kind=link}
{kind=link}